Binary Search Trees in Swift
Dejan Agostini

Binary search trees are one of the most fundamental data structures in computer science. They are very efficient when inserting and searching for elements. And if you're preparing for a technical interview it's more than likely that you'll be asked about them. In this article we'll go over the theory and we'll implement the binary search trees in swift. So, let's get started...
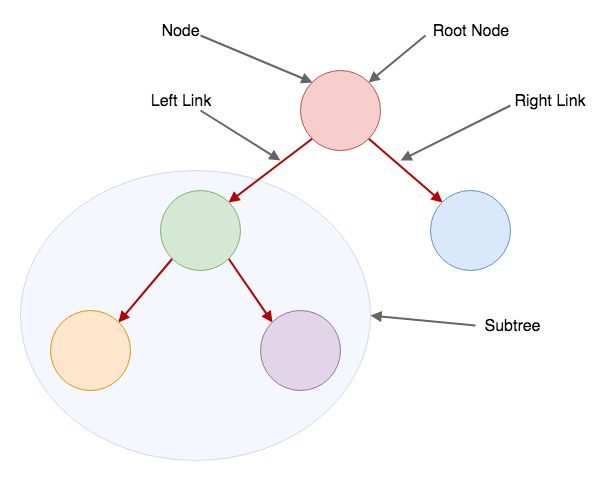 Hopefully the diagram is self explanatory. Just in case it's not clear to you, let me explain it. A binary tree consists of nodes. Each node can have only two children. They can have a left or a right child. A connection between a node and its child is called a 'link'. So a node can have a left and a right link, pointing to a left or a right child.
A node that your left or right link is pointing to can, in turn, have its own children. And so on. The first node in the tree is called the 'root' node. Usually this is the first node inserted into a binary tree, but more on that later. A node that's not a root node, and that's being pointed to can be referred to as a 'subtree'. A subtree consists of the originating node and its children. For example, the green node on our graph is the originating node, and all the nodes this node is pointing to (a more correct way would be to say - nodes that are reachable from this node) are a part of its subtree.
For any node in the tree, the left child is smaller than the node, and the right child is larger than the node. In our implementation we'll use keys and values. You can use any type for the key, as long as it's comparable, and you can use any type for the value... I can go on and on about binary search trees, but I'll spare you the time :) If you want to learn more about them, I recommend the book Algorithms by Sedgewick and Wayne.
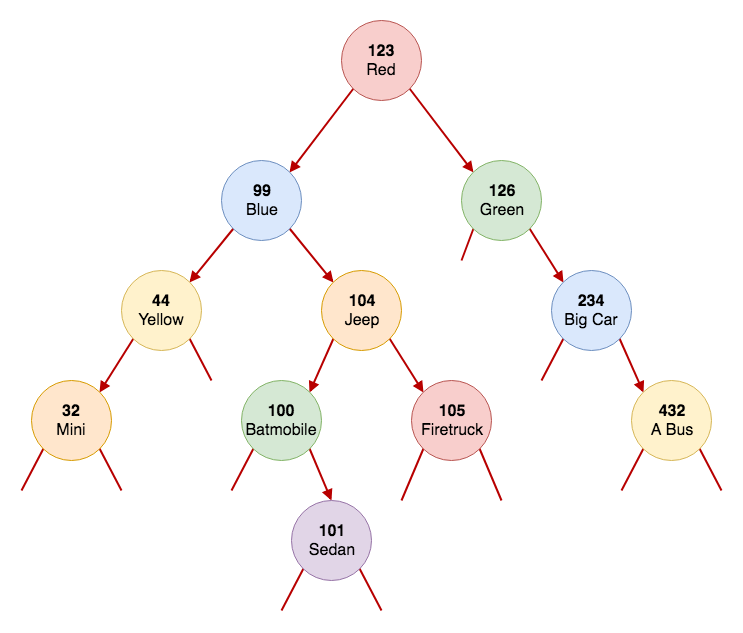
This is an example of the binary tree that we'll be building in this article:
Hopefully the diagram is self explanatory. Just in case it's not clear to you, let me explain it. A binary tree consists of nodes. Each node can have only two children. They can have a left or a right child. A connection between a node and its child is called a 'link'. So a node can have a left and a right link, pointing to a left or a right child.
A node that your left or right link is pointing to can, in turn, have its own children. And so on. The first node in the tree is called the 'root' node. Usually this is the first node inserted into a binary tree, but more on that later. A node that's not a root node, and that's being pointed to can be referred to as a 'subtree'. A subtree consists of the originating node and its children. For example, the green node on our graph is the originating node, and all the nodes this node is pointing to (a more correct way would be to say - nodes that are reachable from this node) are a part of its subtree.
For any node in the tree, the left child is smaller than the node, and the right child is larger than the node. In our implementation we'll use keys and values. You can use any type for the key, as long as it's comparable, and you can use any type for the value... I can go on and on about binary search trees, but I'll spare you the time :) If you want to learn more about them, I recommend the book Algorithms by Sedgewick and Wayne.
This is an example of the binary tree that we'll be building in this article:
 You want to see some code, so let's get to it...
You want to see some code, so let's get to it...
Trees, Nodes and Links
Binary search trees are very simple once you understand some basics. Let's go over some basic terminology to get you more comfortable with it. When you hear people talk about binary search trees you'll hear terms like: root, left child, right child, node, link, subtree... I could fill this paragraph with text explaining what these are, or I can show you a nice diagram like this one:
Hopefully the diagram is self explanatory. Just in case it's not clear to you, let me explain it. A binary tree consists of nodes. Each node can have only two children. They can have a left or a right child. A connection between a node and its child is called a 'link'. So a node can have a left and a right link, pointing to a left or a right child.
A node that your left or right link is pointing to can, in turn, have its own children. And so on. The first node in the tree is called the 'root' node. Usually this is the first node inserted into a binary tree, but more on that later. A node that's not a root node, and that's being pointed to can be referred to as a 'subtree'. A subtree consists of the originating node and its children. For example, the green node on our graph is the originating node, and all the nodes this node is pointing to (a more correct way would be to say - nodes that are reachable from this node) are a part of its subtree.
For any node in the tree, the left child is smaller than the node, and the right child is larger than the node. In our implementation we'll use keys and values. You can use any type for the key, as long as it's comparable, and you can use any type for the value... I can go on and on about binary search trees, but I'll spare you the time :) If you want to learn more about them, I recommend the book Algorithms by Sedgewick and Wayne.
This is an example of the binary tree that we'll be building in this article:
You want to see some code, so let's get to it...
A Bit Of Code
As stated above, our graph will consist of nodes, and a node will have a key, a value, left and a right link. A node will be a generic class, as long as the keys are conforming to the comparable protocol. The node class looks like this:class Node<Key: Comparable, Value> {
var key: Key
var value: Value
var left: Node?
var right: Node?
init(key: Key, value: Value) {
self.key = key
self.value = value
}
}
The left and right links in our node are of type 'Node' because they're pointing to other nodes on the tree. They can be nil because a node doesn't have to have them. If a node has no children it's called a 'Leaf' node. Let's see how this simple class fits into our binary search tree implementation.
Binary Search Tree
The one important thing to remember about binary search trees is that the left node is smaller than the current node and the right node is larger. We'll implement the standard CRUD operations on our tree, and they'll all revolve around this simple principle.Searching
Search operation is quite a simple one. We'll search the tree for a certain key. We'll compare the key with the current node and if the key we're looking for is smaller we know we should look into the left child. If the left child is nil, then the key doesn't exist in the tree. The reverse is true for the right child. Obviously, if the key matches the current node we have our search hit. Let's check out the code:public func get(key: Key) -> Value? {
return get(node: root, key: key)
}
private func get(node: Node<Key, Value>?, key: Key) -> Value? {
guard let aNode = node else {
return nil
}
if key < aNode.key {
return get(node: aNode.left, key: key)
} else if key > aNode.key {
return get(node: aNode.right, key: key)
} else {
return aNode.value
}
}
Now, this would be a good time to talk a bit about recursion...
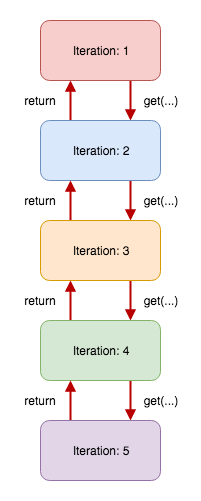 In the 'Iteration 1' we call the 'get' function and return what ever the result of it is. Let's imagine that in 'Iteration 5' we hit our escape condition (the key is equal to the node we're examining in 'Iteration 5'), we return that value to 'Iteration 4' and the value will bubble up all the way to 'Iteration 1'.
In the 'Iteration 1' we call the 'get' function and return what ever the result of it is. Let's imagine that in 'Iteration 5' we hit our escape condition (the key is equal to the node we're examining in 'Iteration 5'), we return that value to 'Iteration 4' and the value will bubble up all the way to 'Iteration 1'.
Recursion
If you look at the code above more carefully, you'll see a function calling itself with different parameters. A function calling itself is what we call a recursive call (or recursive function, or simply, recursion). Recursive functions can simplify your code a great deal. The most important part of a recursive function is the escape condition. Your function must have a path that it can take in which it won't call itself. In the code above we have two escape conditions. One of them is the guard statement and the other is the 'else' branch. If you're not very careful with the escape conditions, or if your escape conditions can't be satisfied, you will end up in the infinite loop and eventually crash. Here's recursion on a diagram:
In the 'Iteration 1' we call the 'get' function and return what ever the result of it is. Let's imagine that in 'Iteration 5' we hit our escape condition (the key is equal to the node we're examining in 'Iteration 5'), we return that value to 'Iteration 4' and the value will bubble up all the way to 'Iteration 1'.
Min And Max
Binary search trees are sorted. If you look at the diagram of the tree above, you'll notice that the left most element will always be the smallest element in the tree and rightmost will always be the largest. We could easily implement min and max functions. For example, this is how a min function would look like:private func min(node: Node<Key, Value>) -> Node<Key, Value> {
guard let leftNode = node.left else {
return node
}
return min(node: leftNode)
}
All we're doing is keep moving left. If the current node doesn't have a left child, we found our minimum and return it. For the max function you would do the opposite.
Inserting
New elements get inserted at the bottom of the tree. When we insert a new element into the tree, we start from the root of the tree and compare the new element with the node we're currently observing. For example, if the new key is less than the root node's key we'll move to the left. We repeat this process until we can't move left or right any more. Until the left or right node is nil. Then we create a new node in the tree and set it as a child of the previous node. Let's see this in code:public func put(key: Key, value: Value) {
root = put(node: root, key: key, value: value)
}
private func put(node: Node<Key, Value>?, key: Key, value: Value) -> Node<Key, Value> {
guard let aNode = node else {
return Node<Key, Value>(key: key, value: value)
}
if key < aNode.key {
aNode.left = put(node: aNode.left, key: key, value: value)
} else if key > aNode.key {
aNode.right = put(node: aNode.right, key: key, value: value)
} else {
aNode.value = value
}
return aNode
}
In our implementation we're also updating the value of the node if the keys match. Imagine we're inserting a 'Car' object into our tree. We already have one object in the tree, which is going to be our root node. The root node will have the key '123' and a car named 'Red'. If we're to insert a new 'Blue' car with a key of '99' we'll call the 'put' function. The function will call the 'put' method recursively (the first 'if' branch in the listing above), pass in its own left node (which is nil) and assign the result of the function call to the left node. When that 'put' method gets called with a nil parameter it will hit the escape condition and create a new node with the passed in key and value.
Here are some pictures :)
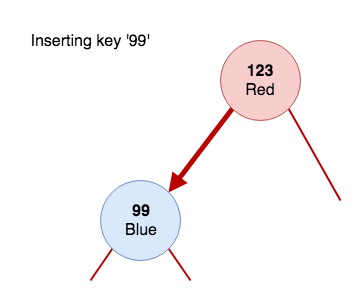 If we wanted to insert a key '104' the diagram would look like this:
If we wanted to insert a key '104' the diagram would look like this:
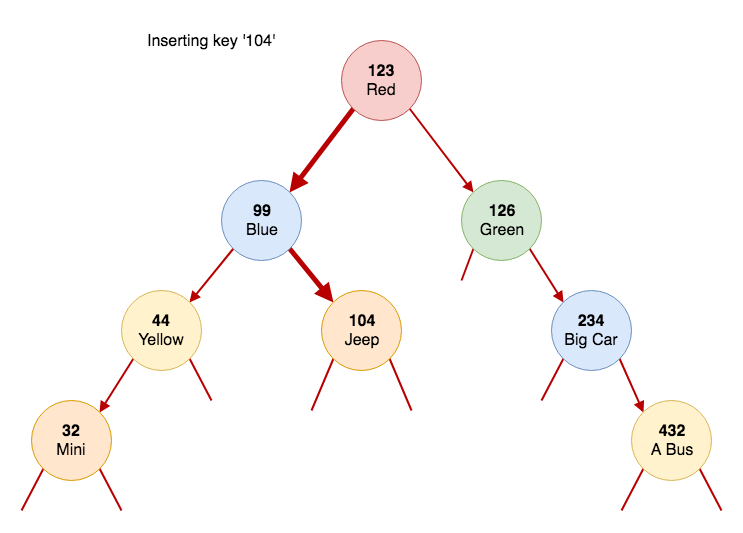 It might help you to visualise recursion like this... You will call the 'put' method once per node, at most. In the node '123' you called 'put' and passed in node '99' to it. From there, you called put for the node '104' and passed the right child of node '99'. Since node '104' does not yet exist, you create it and return it to the caller. Now node '99' got the pointer to node '104' and assigned it to the right child variable.
It might help you to visualise recursion like this... You will call the 'put' method once per node, at most. In the node '123' you called 'put' and passed in node '99' to it. From there, you called put for the node '104' and passed the right child of node '99'. Since node '104' does not yet exist, you create it and return it to the caller. Now node '99' got the pointer to node '104' and assigned it to the right child variable.
If we wanted to insert a key '104' the diagram would look like this:
It might help you to visualise recursion like this... You will call the 'put' method once per node, at most. In the node '123' you called 'put' and passed in node '99' to it. From there, you called put for the node '104' and passed the right child of node '99'. Since node '104' does not yet exist, you create it and return it to the caller. Now node '99' got the pointer to node '104' and assigned it to the right child variable.
Deleting
Deleting a node from the tree can be a bit tricky. When you delete a node, you need to keep the tree in a sorted state. The first to propose the solution to this problem was Hibbard back in 1962. His solution was to replace the node with its successor. To fully understand the Hibbard deletion algorithm we'll go over one specific step of the algorithm first. Deleting the minimum. Let's check out the code for deleting the minimum node.private func deleteMin(node: Node<Key, Value>) -> Node<Key, Value>? {
guard let leftNode = node.left else {
return node.right
}
node.left = deleteMin(node: leftNode)
return node
}
We keep going left in search for a minimum node. When we find our minimum node, we simply return its right child. Returning the right child to the parent node effectively cuts this node off the tree. Because now the parent is pointing to the right child of the node we just deleted, the deleted node has no parents pointing to it. If the right child is nil, this means that this node has not children, so we'll simply return nil to the parent.
From our tree we'll delete the node '99'. After we find the node, we search for its successor. The successor is the next larger node. In our case it's the node with the key '100'. What we do is find the minimum in the right subtree of node '99'. Then we delete that node from the tree and replace its left and right pointers to point to the left and right nodes of node '99'.
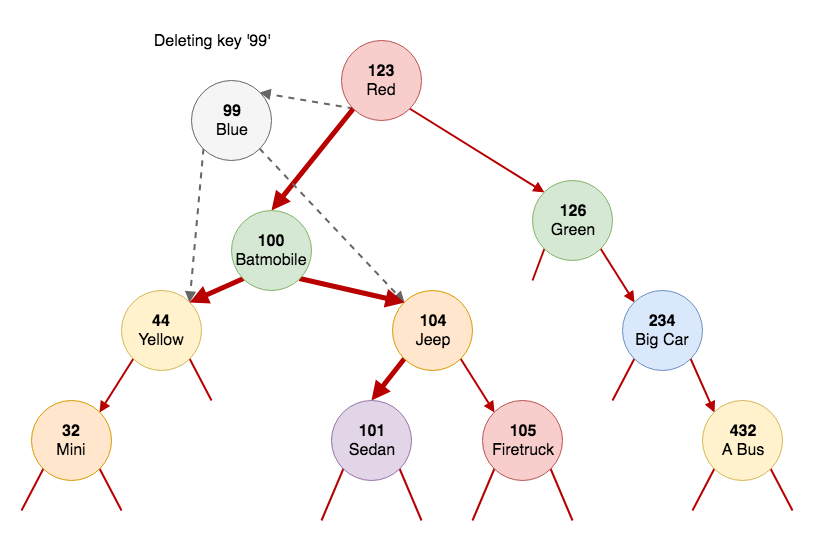 If we look at the node '99' we know that all the nodes on the left are smaller than '99' and all the nodes on the right are larger. If we get the smallest node on the right side of the tree and replace the node '99' with it, the tree will still be sorted. And all the nodes on the right will still be larger than the new node.
Let's see this in code.
If we look at the node '99' we know that all the nodes on the left are smaller than '99' and all the nodes on the right are larger. If we get the smallest node on the right side of the tree and replace the node '99' with it, the tree will still be sorted. And all the nodes on the right will still be larger than the new node.
Let's see this in code.
If we look at the node '99' we know that all the nodes on the left are smaller than '99' and all the nodes on the right are larger. If we get the smallest node on the right side of the tree and replace the node '99' with it, the tree will still be sorted. And all the nodes on the right will still be larger than the new node.
Let's see this in code.
private func delete(node: Node<Key, Value>?, key: Key) -> Node<Key, Value>? {
guard var aNode = node else {
return nil
}
if key < aNode.key {
aNode.left = delete(node: aNode.left, key: key)
} else if key > aNode.key {
aNode.right = delete(node: aNode.right, key: key)
} else {
guard let rightNode = aNode.right else {
return aNode.left
}
guard let leftNode = aNode.left else {
return aNode.right
}
aNode = min(node: rightNode)
aNode.right = deleteMin(node: rightNode)
aNode.left = leftNode
}
return aNode
}
The code for deleting a node is in the 'else' branch. As you can see, deleting a node that has only one child is trivial. After our guard statements we search for the minimum, and assign it to our local variable. Next, we delete the minimum from the right subtree and assign the result of the recursive function to the right child of the new node (node '100'). In the last step, we just take the left child of node '99' and assign it to the left child of node '100'. We'll return the new node '100' to the caller (node '123'). And the caller will set it as its left child in our case.
Subscript
Let's add a bit of syntactic sugar and implement the subscript. This will make our binary search tree a lot more convenient to use:public subscript(key: Key) -> Value? {
get {
return get(key: key)
}
set {
if let value = newValue {
put(key: key, value: value)
} else {
delete(key: key)
}
}
}
With this, our binary search tree will behave like a dictionary and it will be really simple to use.
It's time to test out our tree.
Test Run
We need to create our root node first and then create the tree with it:private func testBST() {
let rootNode = Node(key: 123, value: Car("Red"))
let binaryTree = BinarySearchTree(rootNode)
binaryTree[99] = Car("Blue")
binaryTree[126] = Car("Green")
binaryTree[44] = Car("Yellow")
binaryTree[32] = Car("Mini")
binaryTree[234] = Car("Big car")
binaryTree[432] = Car("A bus")
binaryTree[104] = Car("Jeep")
binaryTree[100] = Car("Batmobile")
binaryTree[101] = Car("Sedan")
binaryTree[105] = Car("Firetruck")
print("::::::::::Testing subscript::::::::::")
print("Blue car: ", binaryTree[99]?.name)
binaryTree[99] = Car("Not Blue")
print("Blue car: ", binaryTree[99]?.name)
binaryTree[99] = nil
print("Blue car: ", binaryTree[99]?.name)
print("::::::::::Testing min/max::::::::::")
print("MIN car: ", binaryTree[binaryTree.min]?.name)
print("MAX car: ", binaryTree[binaryTree.max]?.name)
print("::::::::::Delete max::::::::::")
binaryTree[432] = nil
print("MAX car: ", binaryTree[binaryTree.max]?.name)
}
After that we just start adding our custom objects to the tree and we treat the tree like a dictionary. The console output for the code above looks like this:
::::::::::Testing subscript::::::::::
Blue car: Optional("Blue")
Blue car: Optional("Not Blue")
Blue car: nil
::::::::::Testing min/max::::::::::
MIN car: Optional("Mini")
MAX car: Optional("A bus")
::::::::::Delete max::::::::::
MAX car: Optional("Big car")